

Beyond the Staff Turnover: Tap the Benefits of Low Attrition with Dedicated Teams
Consider this: hiring a new employee costs a company 3-4 times their annual salary. The significant figure emphasizes a crucial reality: retaining talent is more financially advantageous than continual recruitment. Maintaining a low ...

Get Your Remote Team Together. 5 Tips to Collaborate Efficiently in Different...
In the wake of the COVID-19 pandemic, the global workforce shifted ...

Expert Staff Augmentation: Navigating Economic Uncertainties with Flexibility...
What are your thoughts on the financial outlook as the year kicks off? A ...

Innovate or Stagnate: Your 2024 Roadmap to IT Staffing and Outsourcing Trends
A glance at 2024 IT staffing and outsourcing trend articles reveals a repetitive str ...
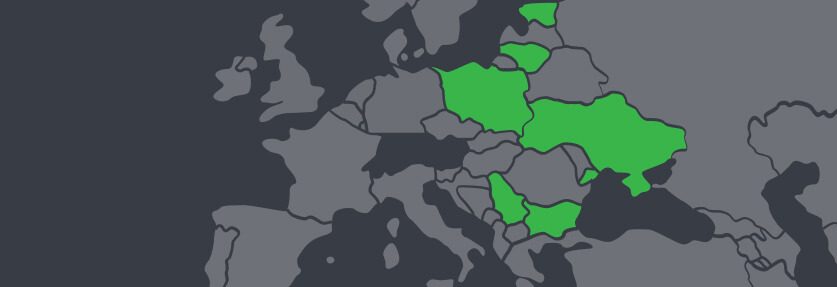
Transforming Your Team With IT Staff Augmentation in CEE Countries
Close your eyes for a moment and think about your favorite lore featuring epic quests, potent opponents, a ...
Nearshoring vs. Offshoring vs. Onshoring: When, Which and Why?
Building a new digital product is challenging. Be it a mobile solution, an IoT app or a website, you’ll need t ...

pwrteams merges with Questers, growing team to 650+
Strategic acquisition strengthens pwrteams’ footprint, access to talent and ability to build cross-border IT and ...

Why You Should Outsource IT Services to Lithuania
Many consider IT outsourcing in Lithuania because it’s a country with many opportunities for international businesses that are looking to ...

Ukrainian IT Industry During the War
It’s not a secret that the reality of Ukraine as a country shifted tremendously once the war broke out on i ...

Patrik Vandewalle is handing over the pwrteams CEO reins to Karel Saurwalt
Patrik Vandewalle, Co-founder and CEO of pwrteams, the international leader in building c ...