

Pagination with Dynamic Data Loading
I’m going to show you how to perform stable loading of pagination data, when an amount of data changes between requests. All samples will be made with C# and LINQ, but they will be simple enough to apply with other languages like Java or SQL. I’ll be using numbers as values, but you can use any comparable data type.
This technique can be applied for Entity Framework.
Pagination of Static Data
Very often, we can’t load a whole data set to display it for a user. Huge amounts of data cause bad user experience and a lot of performance issues. That’s why we use pagination.
General approach to data loading with pagination is quite familiar:
- a data set is represented by a collection of ordered entities
- entities are split on equal portions, called pages
- page size (n) and page number (k) have to be defined
- navigation between pages is executed by 2 operations: Skip and Take
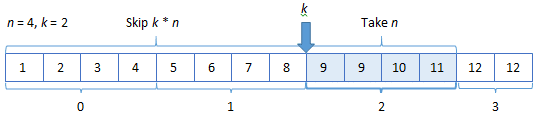
For example, a LINQ expression looks like:
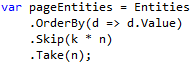
Problem Definition
This technique works fine if you have static data, entities are not removed or entities are added only to the end of the list.
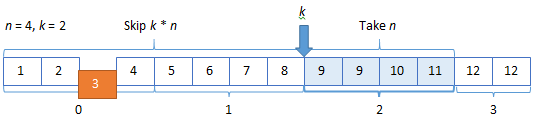
Let’s consider a case when you have taken some data set to the client and some entities are being removed from the server:
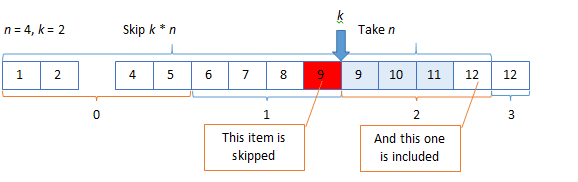
When you execute the next request, part of the data set will be lost:
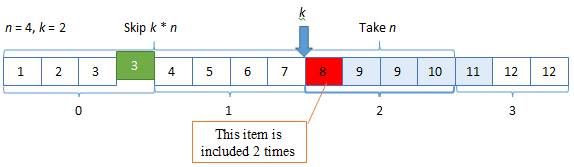
Or if new entities are added, some entities will be included 2 times:
In both cases, you lose data set consistency on the client-side. The end-user won’t see some items or will see some odd ones.
Simplified Solution
The general problem definition is quite simple: we always need to know which element was the last one in the current request and take the next elements in the future request. So, instead of navigating by page number, we need to find the latest entity sent.
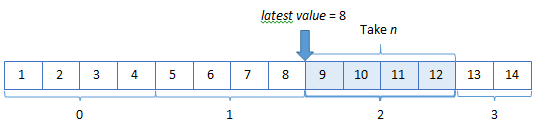
Let’s simplify our task for now: our data set can’t contain duplicates, so all values are unique. In this case, all we need to do is to send the latest value from a collection on the client to the server.
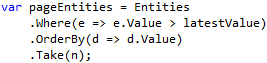
Discover how to bring innovations to life with our unique offering: scale your team globally from one dedicated expert to a fully-owned affiliate company. Register now for a free consultation, just drop us a line.
General Solution

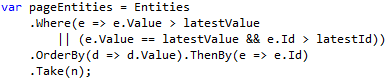
So, let’s consider condition when a data set can contain duplicates. In this case, we need some extra property of the entity that will help us to distinguish one entity from another with the same value – id.
So, now, a pagination algorithm is the following one:
Conclusion
Pagination is very important when you work with huge amounts of data. It isn’t always possible to make pagination by page number and page size. When your data set is dynamic and it can be changed between requests, you need to perform pagination by the latest value and the latest id, as it was described above.
The pagination query can be easily extended to include extra filter expressions or join relative entities.
You can find a sample project with this technique here: https://github.com/ivan-branets/SearchPaging.
